
This web page was created programmatically, to learn the article in its authentic location you’ll be able to go to the hyperlink bellow:
https://aws.amazon.com/blogs/storage/how-anuttacon-scaled-ai-enhanced-gaming-workloads-for-whispers-from-the-star/
and if you wish to take away this text from our website please contact us
The gaming business is present process vital progress, with AI-driven interactive experiences setting new requirements. Anuttacon, an unbiased analysis lab, is dedicated to growing humanistic basic intelligence that permits seamless, real-time interactions throughout textual content, voice, visuals, and extra. Their mission is to create multimodal AI able to real emotional understanding and expressive communication—expertise that each thinks and feels.
When getting ready to launch their extremely anticipated sport, “Whispers from the Star,” Anuttacon encountered a standard but vital business problem: managing huge, unpredictable site visitors spikes whereas ensuring of optimum efficiency throughout a number of Amazon Web Services (AWS) Regions and addressing GPU capability constraints.
In this weblog, we discover how Anuttacon efficiently carried out a scalable structure for “Whispers from the Star” utilizing AWS companies. The resolution is very related for gaming corporations dealing with related points with unpredictable site visitors and GPU useful resource limitations. Game builders, architects, and technical leaders engaged on AI-enhanced gaming functions can discover worthwhile architectural patterns and finest practices on this dialogue.
The problem: past conventional scaling
Traditional scaling approaches fall quick when coping with the distinctive calls for of recent gaming workloads, significantly these enhanced with AI options. Anuttacon’s “Whispers from the Star” offered a number of interconnected scaling challenges that pushed standard strategies to their limits.
Dynamic site visitors patterns
The sport skilled huge site visitors spikes in the course of the preliminary launch, usually reaching 10-50x regular capability. This peak demand makes it economically unfeasible to order all needed situations and storage prematurely. Daily engagement cycles create various site visitors patterns as gamers have interaction with AI-enhanced gameplay options at totally different instances all through the day, making static capability allocation inefficient.
Resource constraints
AI-enhanced options want GPU situations, which have various availability throughout totally different AWS Regions. The workforce wanted to provision infrastructure inside minutes to keep up participant expertise throughout site visitors bursts whereas implementing dynamic scaling to keep away from over-provisioning throughout off-peak hours and ensure of capability throughout peaks.
Technical necessities
The structure wanted to attenuate downtime to ensure that gamers had a constantly good expertise. This necessitated uniform efficiency no matter geographic location or underlying infrastructure constraints.
The resolution: stateless multi-Region structure
Anuttacon carried out a complicated multi-Region structure that makes use of stateless service designed to allow versatile scaling and capability administration throughout AWS Regions.
Game service structure
“Whispers from the Star” consists of three main gaming service parts: core sport service, renderer service, and inference service. They work collectively to ship a whole gaming expertise within the following methods, additionally proven within the following determine.

The core sport service handles important features, corresponding to person login, fee processing, and sport state administration. This service maintains person information and sport development, necessitating cautious state administration and information consistency.
The renderer service processes graphics and visible parts, producing the visible output that gamers see. This service is designed to be stateless, which permits it to run on any obtainable infrastructure with no need particular information or configuration.
The inference service powers the AI-enhanced options of the sport, working machine studying (ML) fashions to generate clever responses and behaviors. Like the renderer service, the inference service is designed to be stateless, enabling it to function on any obtainable compute assets.
The design alternative of creating each companies utterly stateless allows them to run on any obtainable Amazon Elastic Kubernetes Service (Amazon EKS) cluster in any AWS Region with out necessitating information migration or particular configuration. When capability constraints happen in a single AWS Region, workloads can seamlessly transfer to AWS Regions with obtainable assets.
Architecture parts
The resolution consists of three built-in parts working collectively to supply seamless scaling and capability administration, as proven within the following determine.
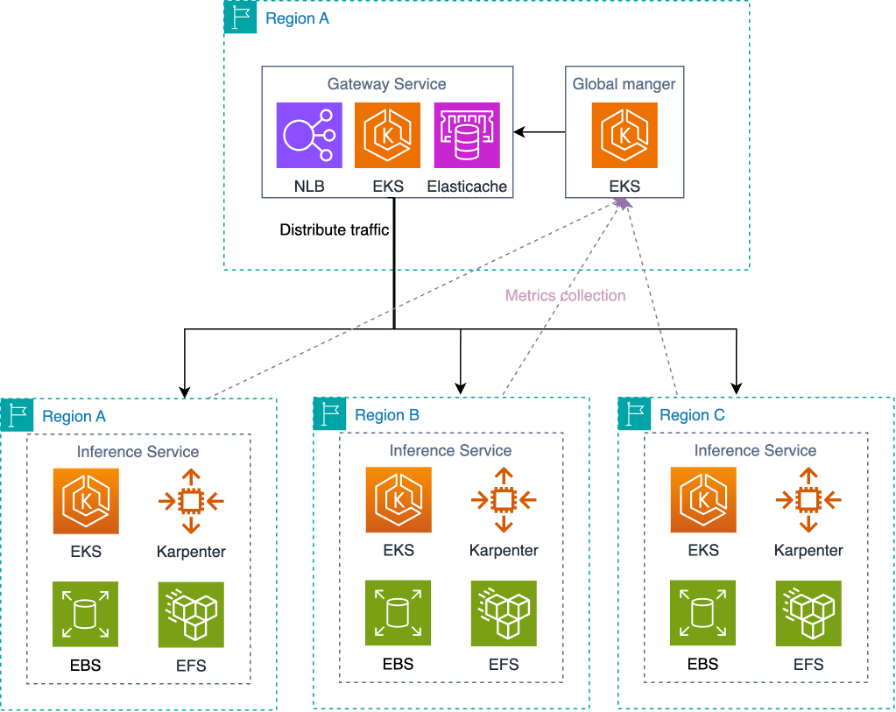
Regional EKS clusters
Each AWS Region comprises an unbiased EKS cluster that operates autonomously, scales independently based mostly on native demand, and maintains its personal capability swimming pools and useful resource allocation. These clusters embrace optimized storage configurations as a part of their setup to allow sooner useful resource provisioning for the stateless companies.
Each Regional cluster makes use of Amazon EKS for managed Kubernetes orchestration with integration with AWS companies for seamless scaling and assist for various workload sorts corresponding to each CPU and GPU intensive functions.
Karpenter supplies clever node provisioning that robotically selects optimum occasion sorts based mostly on workload necessities, provisions nodes inside minutes quite than needing guide intervention, and helps various occasion households to keep away from capability constraints.
Gateway service
The gateway service manages the routing of incoming requests throughout all Regional clusters. It repeatedly screens the well being standing of backend companies throughout totally different AWS Regions via energetic well being checks. When any Regional cluster reveals indicators of abnormality or degradation, the gateway service quickly detects these points and robotically removes the unhealthy companies from the routing pool. It distributes site visitors based mostly on real-time utilization metrics and well being standing throughout AWS Regions, which makes positive of optimum load distribution and efficiency. The gateway service makes clever routing choices to direct participant requests to essentially the most applicable wholesome regional cluster based mostly on the present capability, efficiency metrics, and repair well being standing.
Global supervisor
The international supervisor supplies clever orchestration and capability administration throughout all regional clusters and their constituent Availability Zones (AZs). It repeatedly screens utilization and capability constraints at each the Regional and AZ ranges, which robotically rebalances every cluster’s goal capability to optimize useful resource allocation and keep efficiency requirements. Managing assets on the AZ granularity allows the worldwide supervisor to make extra exact scaling choices and higher deal with localized capability constraints. The international supervisor works in coordination with the gateway service to ensure that each routing choices and capability planning are aligned throughout AWS Regions and AZs.
Addressing technical implementation problem: inference chilly begin
One of essentially the most vital challenges within the inference service is the chilly begin drawback. AI fashions and their related containers are sometimes massive, usually a whole lot of gigabytes in measurement. When new situations launch, they need to obtain these massive container photos and AI fashions earlier than they’ll start serving inference requests. Without cautious optimization, this course of can take 10+ minutes, creating unacceptable delays throughout site visitors spikes when fast scaling is most crucial.
Previous container scaling for the inference workloads resolution follows a predictable however gradual sample. First, Amazon Elastic Compute Cloud (Amazon EC2) situations launch, which usually takes 30-60 seconds. Then, containers should obtain massive photos containing AI frameworks, libraries and fashions from Amazon Elastic Container Registry (Amazon ECR), usually needing 10-Quarter-hour for inference workloads with massive mannequin information. Finally, containers initialize and cargo fashions into reminiscence, including one other 10-Quarter-hour. The complete time can vary from 20-Half-hour, which is unacceptable for gaming workloads experiencing sudden site visitors spikes.
Addressing the implementation problem, Anuttacon developed a multi-faceted strategy to handle the chilly begin drawback for his or her inference service. Its resolution concerned pre-building customized Bottlerocket Amazon Machine Images (AMIs) with embedded containers to cut back the container obtain time, utilizing Amazon EBS Provisioned Rate for Volume Initialization to hurry up Amazon EBS initialization, and utilizing Amazon Elastic File System (Amazon EFS) to load massive ML fashions.

Custom Bottlerocket EBS Snapshot function a vital enabler for this strategy by leveraging the info quantity characteristic of the Bottlerocket working system. This permits container photos to be prefetched quite than downloaded from ECR throughout deployment, eliminating obtain time and bettering startup efficiency.
Amazon EBS Provisioned Rate for Volume Initialization additional accelerates this course of by guaranteeing these information volumes are created and initialized inside predictable timeframes. This AWS characteristic considerably reduces the time required to create absolutely performant EBS volumes from snapshots, enabling sooner occasion startup instances throughout scaling occasions.
During peak demand, the client should create 200 EBS volumes per minute to scale out successfully. Using Amazon EBS Provisioned Rate for Volume Initialization on the most fee of 300 MiB/s per quantity, EBS ensures that information volumes containing prefetched container photos (187GB of precise information) are prepared inside 6 minutes. This optimization proves significantly worthwhile since high-performance storage is just required in the course of the preliminary mannequin loading part.
The structure additionally makes use of Amazon EFS as a high-performance file system for ceaselessly accessed AI fashions. By combining Bottlerocket’s information quantity prefetching functionality with EBS Provisioned Rate for Volume Initialization and Amazon EFS for giant mannequin file storage, the system achieves substantial efficiency enhancements. EBS hundreds the prefetched container picture information (187GB) inside 6 minutes whereas concurrently loading extra AI fashions (50GB) from EFS in parallel. This parallel loading strategy ensures complete time from container begin to mannequin completion stays below 7 minutes—a big enchancment over the earlier implementation.
Cross-Region scaling finest practices
Anuttacon carried out a number of battle-tested practices to verify of dependable scaling throughout AWS Regions. Multi-Region deployment supplies geographic distribution for fault tolerance and capability availability. Diversified occasion households unfold workloads throughout a number of EC2 occasion sorts to keep away from capability constraints in any single occasion household. A heat pool buffer maintains pre-warmed situations that present time for extra scaling to happen throughout site visitors spikes. Retry mechanisms with Karpenter present computerized retry logic for node provisioning failures. Backpressure and queuing implement clever site visitors administration to deal with load spikes gracefully with out overwhelming backend methods.
Key takeaways for designing gaming infrastructure
This structure demonstrates a number of essential rules for contemporary gaming workloads.
Stateless service design
The key architectural precept is designing companies to be stateless wherever potential. Stateless companies can run on any obtainable infrastructure with no need information migration or particular configuration, enabling true multi-Region flexibility and fast scaling in response to capability constraints.
Storage optimization for giant AI fashions
Pre-loading containers into customized AMIs and EBS Snapshots, utilizing Amazon EBS Provisioned Rate for Volume Initialization to load the containers and utilizing Amazon EFS to load fashions can considerably enhance scaling efficiency for inference workloads. This strategy addresses the chilly begin drawback that historically slows AI-enhanced gaming functions.
Multi-Region useful resource balancing
Intelligent site visitors distribution based mostly on real-time capability allows higher useful resource utilization and constant participant expertise. This strategy is especially worthwhile for GPU workloads the place capability constraints range considerably by AWS Region.
Conclusion
Anuttacon’s success with “Whispers from the Star” showcases how considerate structure design can tackle the distinctive challenges of recent gaming workloads. Focusing on stateless service design and utilizing AWS capabilities, significantly Amazon EBS Provisioned Rate for Volume Initialization, to handle chilly begin challenges enabled them to create an answer that scales effectively, manages prices successfully, and delivers distinctive participant experiences.
The gaming business’s evolution towards AI-enhanced experiences and international participant engagement necessitates infrastructure that may adapt shortly to altering calls for. This structure sample supplies a confirmed blueprint for gaming corporations dealing with related scaling challenges.
To be taught extra about Amazon EBS Provisioned Rate for Volume Initialization, go to the AWS News weblog.
This web page was created programmatically, to learn the article in its authentic location you’ll be able to go to the hyperlink bellow:
https://aws.amazon.com/blogs/storage/how-anuttacon-scaled-ai-enhanced-gaming-workloads-for-whispers-from-the-star/
and if you wish to take away this text from our website please contact us


