
This web page was created programmatically, to learn the article in its authentic location you may go to the hyperlink bellow:
https://chipsandcheese.com/p/skymont-in-gaming-workloads
and if you wish to take away this text from our web site please contact us
E-Cores are central in Intel’s CPU technique. Their small space footprint helps Intel obtain excessive multithreaded efficiency in a low space footprint. But E-Cores don’t derive their energy from numbers alone, as a result of they nonetheless have important per-core efficiency. Skymont, the E-Cores in Intel’s newest Arrow Lake desktop platform, can attain 4.6 GHz and maintain 8 micro-ops per cycle. Workloads delicate to per-thread efficiency, reminiscent of video games, will nonetheless profit from Lion Cove’s even greater clock speeds and deeper reordering capability. Still, Skymont’s dealing with of gaming workloads remains to be attention-grabbing partially as a curiosity, and partially as a result of it could possibly present playable efficiency throughout a wide range of titles. Testing right here was carried out utilizing Intel’s Arc B580 and DDR5-6000 28-36-36-36 reminiscence.

Top-down evaluation accounts for why core width went under-utilized by trying on the rename/allocate stage. It’s the narrowest stage within the pipeline, which means that pipeline slots misplaced there’ll carry down common throughput. Skymont is usually backend-bound, which is when the renamer had micro-ops to ship downstream, however the out-of-order backend couldn’t settle for them. Lion Cove is in an identical state of affairs, which isn’t shocking as a result of each cores share a reminiscence subsystem after L2, and backend certain losses usually happen due to reminiscence entry latency.
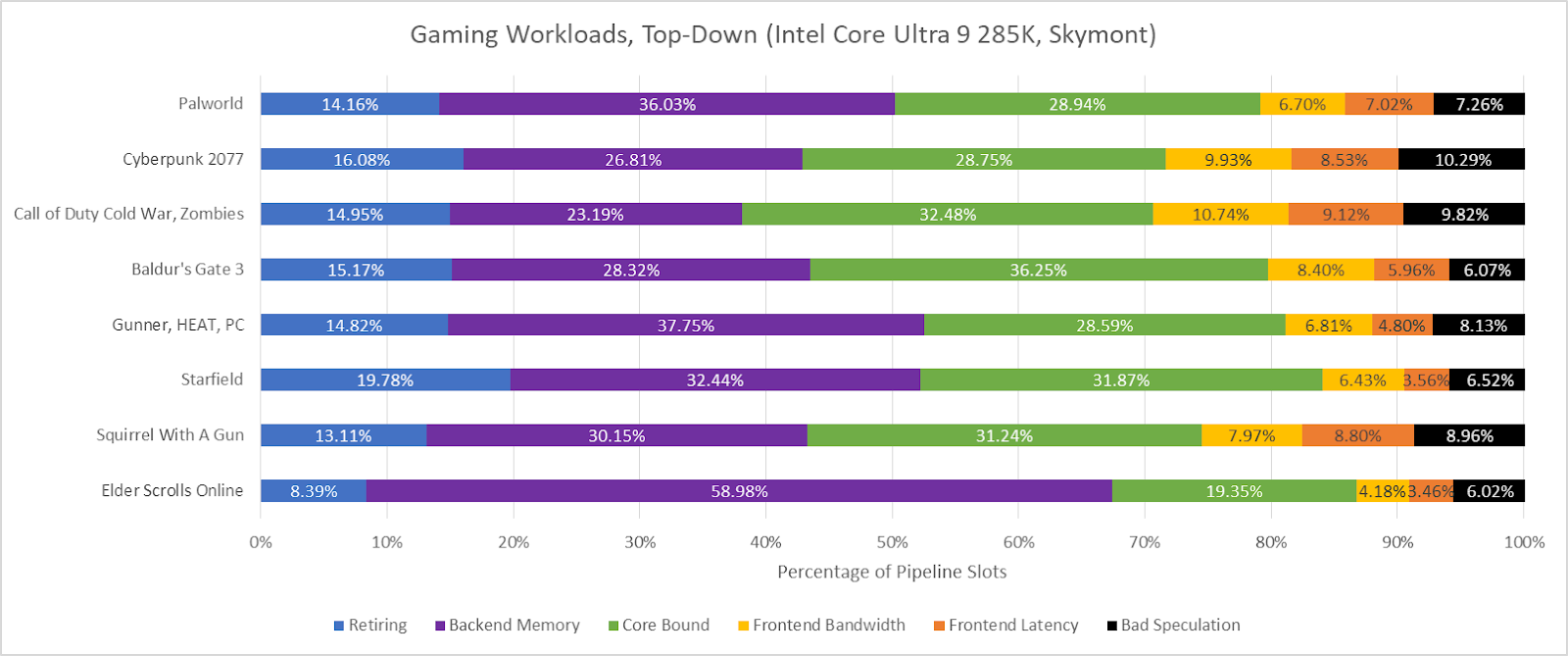
Skymont doesn’t have occasions or unit masks to categorize backend certain slots into core-bound and reminiscence certain ones. AMD suggests doing so by how usually instruction retirement was blocked by a load versus one other instruction sort. That technique could be roughly replicated on Skymont, which has an occasion that counts cycles when retirement was blocked by a load. Setting cmask=1 and the invert bit for the retirement slot rely occasion offers the overall variety of cycles with retirement stalled.
A big portion of retirement stalls are attributable to reminiscence hundreds, however a shocking portion are attributable to different causes. There’s some distinction on this technique in comparison with AMD’s, as a result of retirement could be stalled for causes apart from an incomplete instruction. For instance, the ROB might be empty following a expensive mispredict or an exception. Still, these “core bound” slots are value a better look.
Resource unavailability is the most typical cause that the backend can’t settle for incoming micro-ops. The core’s reorder buffer, register recordsdata, reminiscence ordering queues, and different constructions can replenish as micro-ops pile up forward of a protracted latency one. The first construction that fills then causes the renamer to stall. Skymont has a big 416 entry reorder buffer (ROB), which in principle lets it preserve practically as many micro-ops in flight as excessive efficiency cores like Zen 5 (448) and Lion Cove (576). However, Skymont usually runs into different limitations earlier than its ROB fills up. Its largely distributed scheduling scheme doesn’t do in addition to Zen 5’s extra unified one. Microbenchmarking suggests Zen 5 and Skymont have related scheduler entry counts throughout broad instruction classes, however a unified scheduler is usually extra environment friendly for the same entry rely. Zen 5 not often runs out of scheduler entries and fills its ROB extra usually, displaying that benefit. Skymont’s register recordsdata and reminiscence ordering queues are adequately sized and barely present up as a limitation. But useful resource stalls aren’t the one cause behind backend-bound throughput losses.
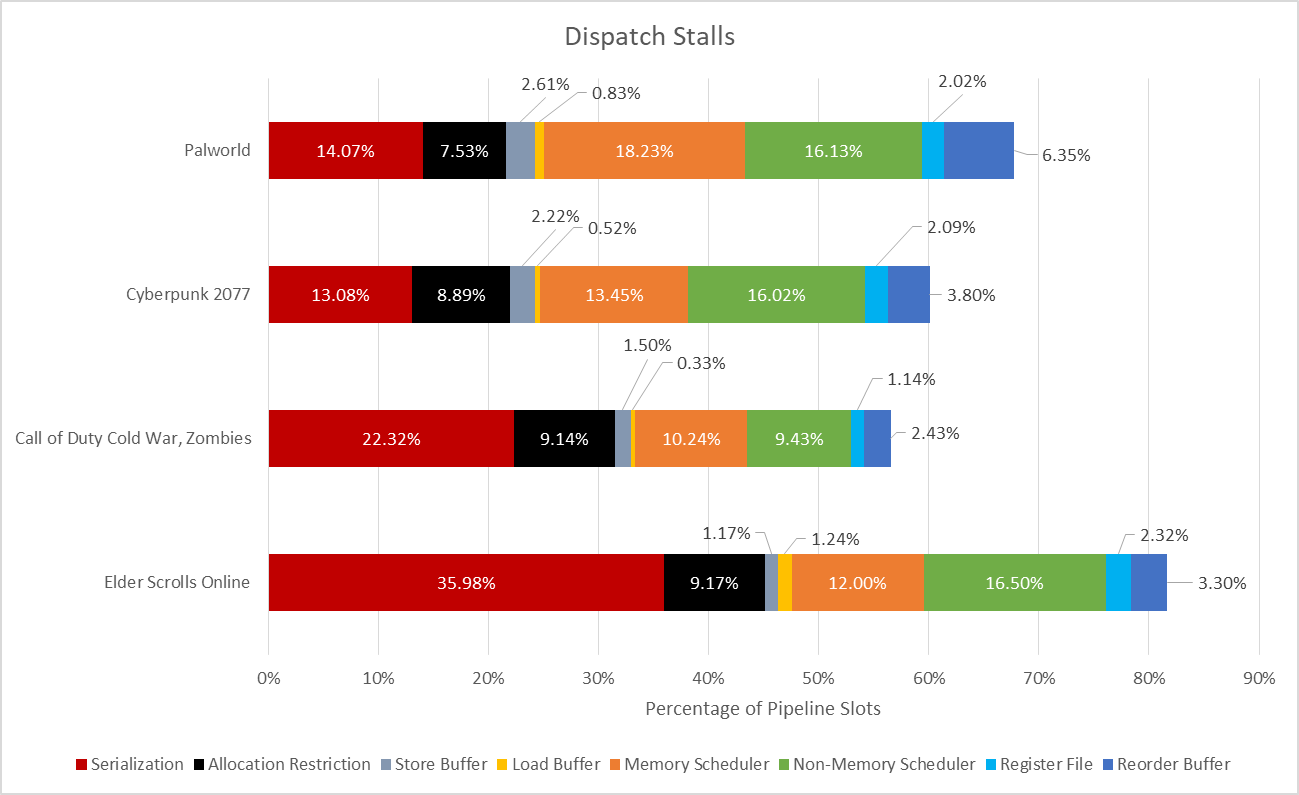
Allocation restrictions aren’t immediately documented besides in efficiency monitoring occasions. One principle is that the distributed schedulers have limitations on what number of micro-ops they’ll settle for from the renamer every cycle. Arm clearly paperwork these restrictions for his or her Cortex X1 core. Perhaps Skymont has related restrictions. In any case it’s not an enormous deal. Getting rid of allocation restrictions would get micro-ops into the backend quicker, however the backend will inevitably run right into a useful resource stall if lengthy latency directions aren’t retired shortly sufficient.

Finally, “serialization” refers to conditions when the core can’t reorder previous a sure instruction. I’m undecided how usually this occurs on different cores, however Zen 5’s efficiency counters do attribute a considerable portion of backend stalls to miscellaneous causes. Skymont for its half can break down serialization associated stalls into a couple of sub-categories, permitting for a better look.
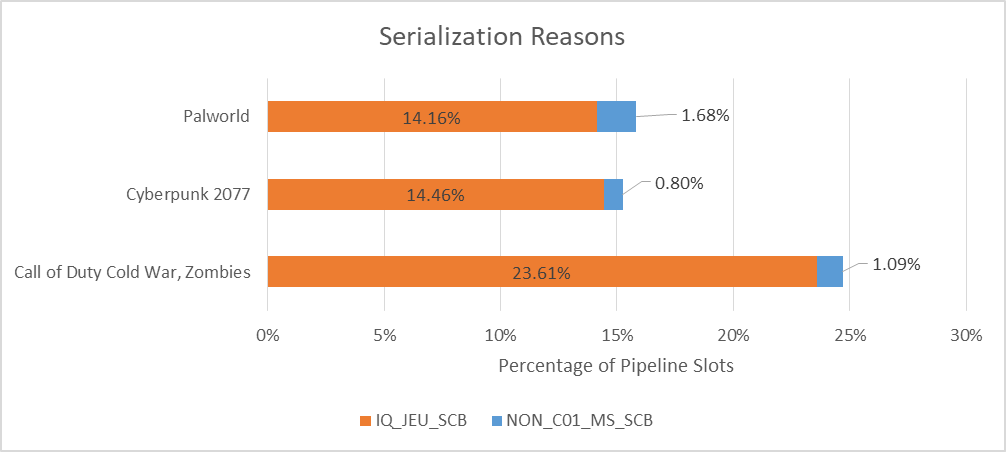
IQ_JEU_SCB refers to “an IQ [instruction queue] scoreboard that stalls allocation until a specified older uop retires or (in the case of jump scoreboard) executes. Commonly executed instructions with IQ scoreboards include LFENCE and MFENCE.” Intel’s description implies Skymont has instances the place it has to dam additional directions from moving into the backend till the JEU (bounce execution unit?) finishes executing a bounce instruction. I’m undecided what triggers this. LFENCE (load fence) and MFENCE (reminiscence fence) are specific software program reminiscence limitations, and require the core to serialize reminiscence accesses. I don’t assume there’s a lot the core can do to keep away from that mandated serialization.
Other serialization instances are uncommon. C01_MS_SCB, not proven above, counts instances when a UMWAIT or TPAUSE instruction put the core into a light-weight C0.1 sleep state. NON_C01_MS_SCB factors to “micro-sequencer (MS) scoreboard, which stalls the front-end from issuing from the UROM until a specified older uop retires. The most commonly executed instruction with an MS scoreboard is PAUSE”. Those stalls come up a bit, so maybe video games are utilizing spinlocks with the PAUSE instruction.
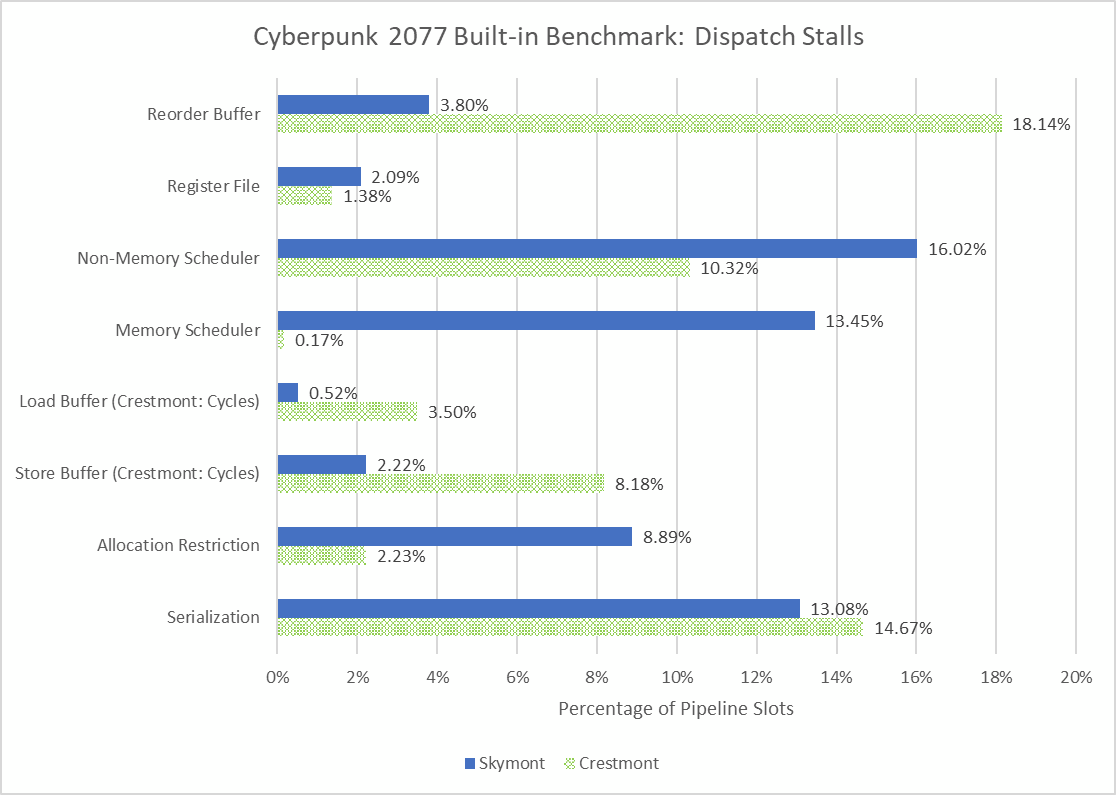
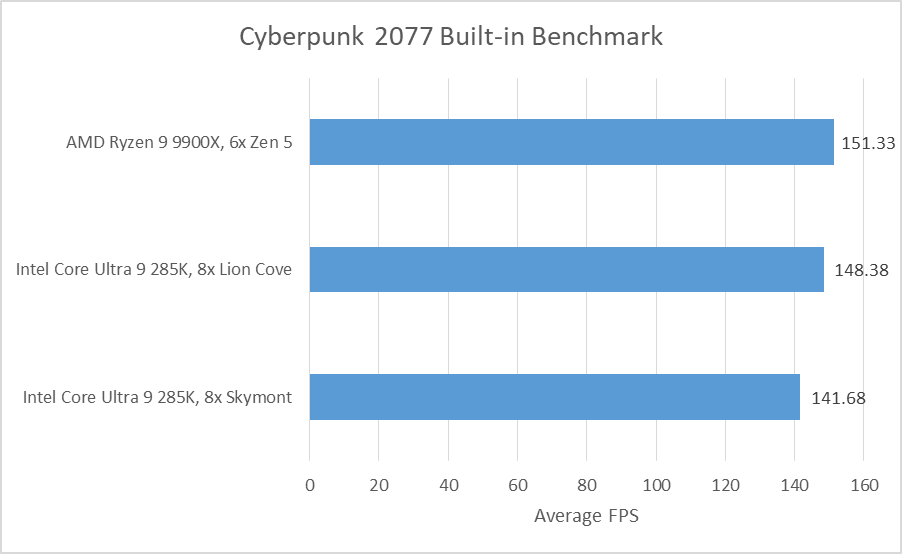
Skymont is notable for massively rising reordering capability in comparison with Crestmont, its fast predecessor. Doing a direct comparability between the 2 is unimaginable as a result of I’ve Crestmont in a Meteor Lake laptop computer and not using a discrete GPU. However, operating Cyberpunk 2077’s built-in benchmark to get a common image suggests Crestmont has a better time reaching the restrict of its 256 entry reorder buffer. Other limiting elements are nonetheless important on Crestmont, however useful resource stall causes have moved round in comparison with Skymont. For instance, Cresmont not often runs out of reminiscence scheduler entries, although non-memory scheduler entries nonetheless really feel stress. Allocation restrictions are extra of a problem on Skymont, maybe as a result of an 8-wide rename/allocate group is extra prone to include extra micro-ops destined for a similar scheduler. Serialization stays a problem on each cores.
Cache misses are typically the most typical lengthy latency directions, and thus contribute closely to useful resource stalls. Skymont has a typical triple-level information cache hierarchy, with a 32 KB L1D, and a 4 MB L2 shared throughout a quad core cluster. Arrow Lake offers a 36 MB L3 that’s shared throughout all cores. With a bigger L2, smaller L1D, and no L1.5D, Skymont leans more durable on its L2 in comparison with the Lion Cove P-Cores. Just like Lion Cove, L2 misses should cope with ~14 ns of L3 latency, which is excessive in comparison with AMD’s sub-9ns L3 latency.
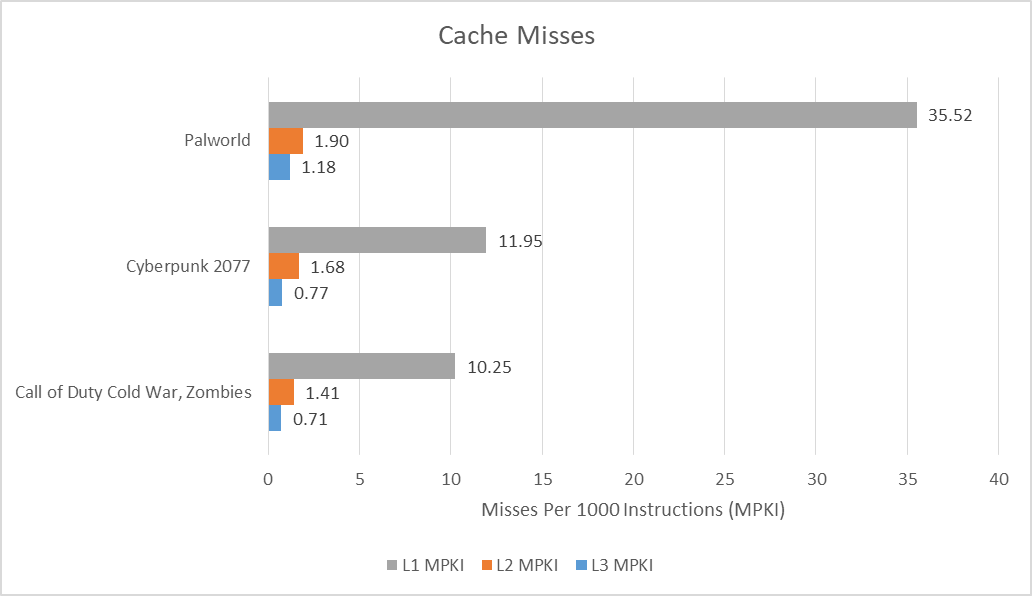
Skymont can break down how usually the core was stalled attributable to a L1D demand miss. “Demand” signifies an entry was initiated by an instruction, versus a prefetch, however doesn’t assure that instruction truly retired. Intel didn’t state what standards it makes use of to find out if the core is stalled. Older cores like Skylake had an identical occasion that, for instance, would take into account the core L2 certain if there’s a pending load from L2, no L2 miss in flight, and no micro-op may start execution that cycle.
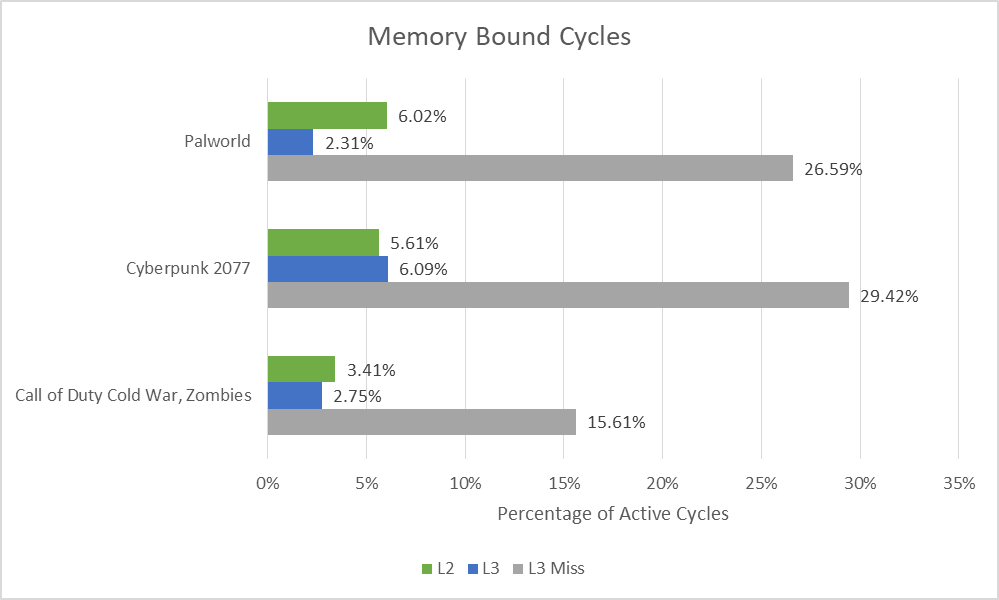
DRAM latency poses the largest problem for Skymont. L2-bound cycles are low, suggesting Skymont’s out-of-order engine can usually preserve sufficient directions in flight to cover L2 latency. High L3 latency isn’t too painful, possible for 2 causes. The most evident is that Skymont’s massive 4 MB L2 lets it preserve many accesses off L3. For perspective, 4 MB is as massive because the L3 cache on cell and console Zen 2 variants. The second is that Skymont’s decrease clock velocity means it has much less potential efficiency to start with. An analogy is {that a} much less streamlined plane may fear much less about air resistance as a result of it flies at decrease speeds. It’s not technically a bonus, however it does imply the core has much less to lose whereas ready for information from L3.
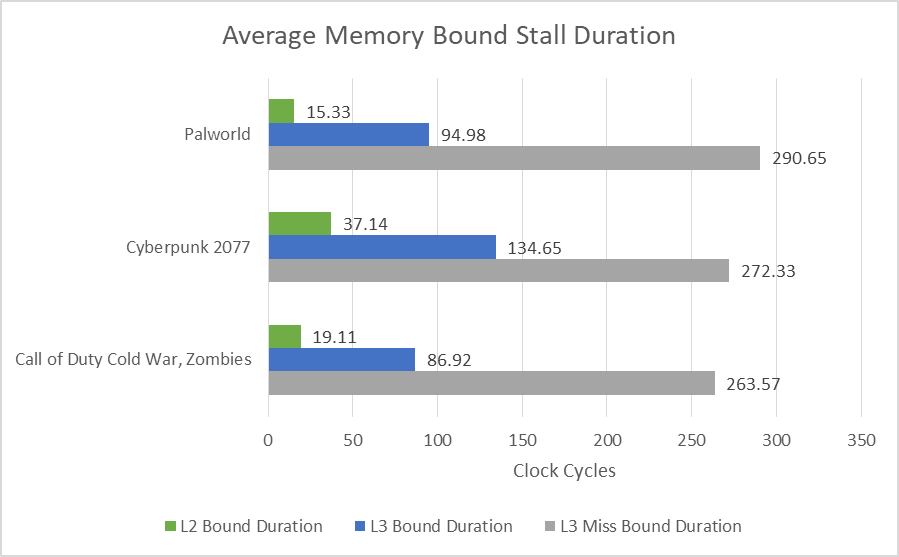
Setting the sting bit permits counting the variety of stall occurrences. Dividing stall cycle rely by incidence rely offers common stall length. Those figures are unusual, as a result of common stall durations exceed measured cache latency for L2 and L3. Perhaps loads of blocked directions have a number of inputs that come from the desired cache stage. Or, Skymont may use completely different standards than Skylake to find out when the core is reminiscence certain. For instance, it might be indicating how lengthy the core had directions caught ready on information from a specified reminiscence hierarchy stage, even when different directions had been in a position to execute within the meantime.
Skymont’s frontend isn’t a limiting issue, due to backend-related throughput losses. However, Skymont does have attention-grabbing efficiency counters on the frontend, so it’s value a glance. Intel breaks down frontend associated stalls into bandwidth and latency certain classes by why the frontend under-fed the core. In distinction, Zen 5 and Lion Cove take into account a slot frontend latency certain if the frontend delivered no micro-ops that cycle, and bandwidth-bound if it delivered some micro-ops, however not sufficient to fill all renamer slots. Specifically:

Splitting up latency versus bandwidth certain slots on this means may make extra sense for Skymont, as a result of its clustered decoder is much less liable to dropping throughput from taken branches in comparison with a standard straight-line decoder. Basically, Intel considers Skymont frontend bandwidth certain if the decoders had incoming directions, however was unable to course of them effectively. If the frontend is under-fed due to department predictor delays, cache misses, or TLB misses, it’s thought-about latency certain.
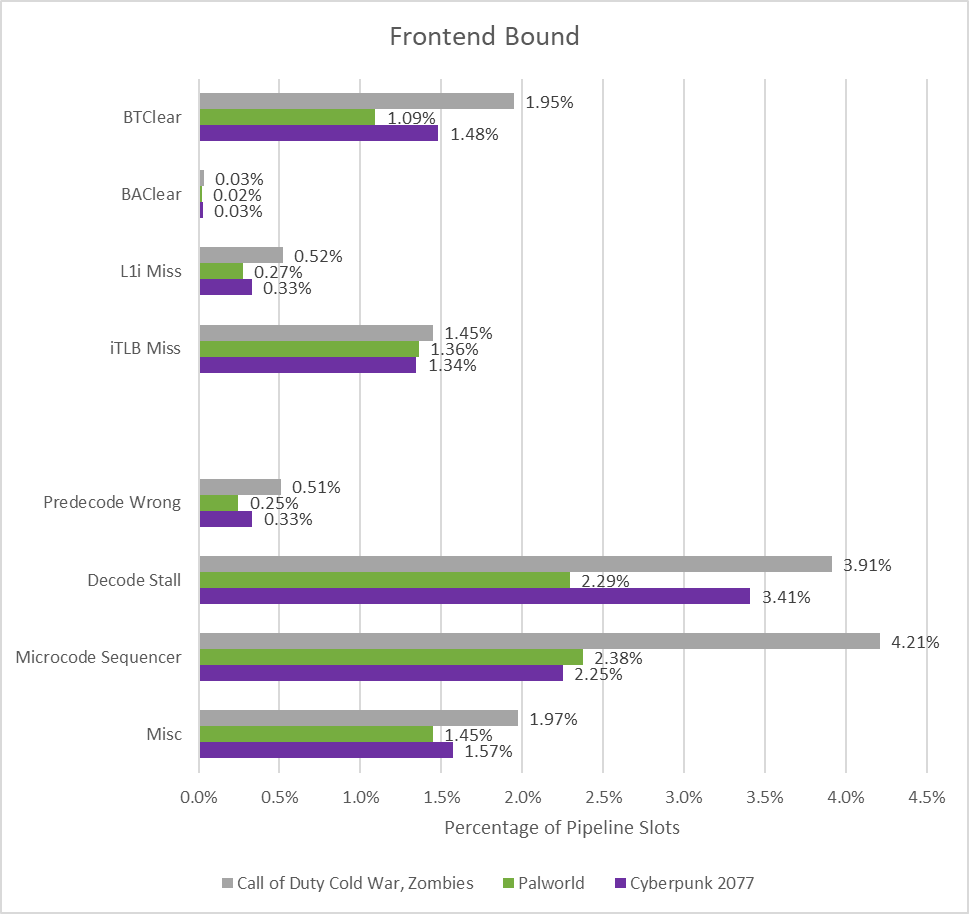
Delays from all sources are minor, although decode stalls and hitting microcode price some throughput. I’m undecided what causes decode stalls on Skymont. Intel’s optimization information notes that load balancing points between the decoders or “other decode restrictions” will usually be indicated by the decode stall unit masks. Microcode is usually used for directions that aren’t dealt with by fast-path {hardware} within the execution engine. Density optimized cores are inclined to have much less space funds for rarer and tougher operations, and will execute them with a number of micro-ops (which could come from microcode). CPU designers will attempt to fastidiously have a look at what directions purposes use and reduce micro-op growth. But that process will likely be more durable for density optimized cores like Skymont.
Skymont’s department prediction accuracy is sweet sufficient in video games. I’m not going to look too far into Palworld and Call of Duty, as a result of I think the margin of error is sort of excessive. Curiously Skymont achieved higher prediction accuracy and roughly 25% fewer mispredicts per instruction in Cyberpunk 2077’s built-in benchmark.
Skymont will not be a P-Core and doesn’t compete for optimum efficiency. However, it subjectively turns in an excellent efficiency in video games. I performed a wide range of video games on the Core Ultra 9 285K with affinity set to the 16 E-Cores. All had been in a position to obtain greater than playable framerates with few stutters or different points. It’s an excellent showcase of what a density optimized core can do on fashionable course of nodes, whereas additionally highlighting the difficulty of diminishing returns when pushing for optimum efficiency. I think a hypothetical chip with simply Skymont cores may do fairly effectively in isolation.
That doesn’t imply all E-Core chips can go mainstream anytime quickly, or that Intel’s E-Core line can displace their P-Cores. If historical past is something to go off, an E-Core would wish to exceed P-Core efficiency in various purposes earlier than it could possibly put on each hats. Long way back, Intel’s P6-based Pentium M was in a position to outmatch Netburst-based Pentium 4 chips in a surprisingly large variety of workloads, foreshadowing Intel’s transfer to ditch Netburst in favor of a beefed up P6 variant within the Core 2 collection. Skymont isn’t the place Pentium M was in that period, nor does Intel’s Lion Cove P-Core endure the inefficiencies Netburst did. But there’s no ignoring that Skymont is a really succesful core by itself. Intel’s E-Core staff deserves credit score for packing all that efficiency right into a small space footprint.
If you just like the content material then take into account heading over to the Patreon or PayPal if you wish to toss a couple of bucks to Chips and Cheese. Also take into account becoming a member of the Discord.
This web page was created programmatically, to learn the article in its authentic location you may go to the hyperlink bellow:
https://chipsandcheese.com/p/skymont-in-gaming-workloads
and if you wish to take away this text from our web site please contact us

