
This web page was created programmatically, to learn the article in its authentic location you may go to the hyperlink bellow:
https://developers.googleblog.com/en/building-the-next-generation-of-physical-agents-with-gemini-robotics-er-15/
and if you wish to take away this text from our website please contact us

Today, we’re making our state-of-the-art robotics embodied reasoning mannequin, Gemini Robotics-ER 1.5, obtainable to all builders. This is the primary Gemini Robotics mannequin to be made broadly obtainable. It acts as a high-level reasoning mannequin for a robotic.
This mannequin focuses on capabilities essential for robotics, together with visible and spatial understanding, activity planning, and progress estimation. It may also natively name instruments, like Google Search to seek out info, and might name a vision-language-action mannequin (VLA) or every other third-party user-defined features to execute the duty.
You can get began constructing with Gemini Robotics-ER 1.5 right this moment in preview through Google AI Studio and the Gemini API.
This mannequin is designed for duties which can be notoriously difficult for robots. Imagine asking a robotic, “Can you kind these objects into the proper compost, recycling and trash bins?” To complete this task, the robot needs to look up the local recycling guidelines on the internet, understand the objects in front of it and figure out how to sort them based on local rules, then do all the steps to complete putting them away. Most daily tasks, like this one, take contextual information and multiple steps to complete.
Gemini Robotics-ER 1.5 is the primary considering mannequin optimized for this sort of embodied reasoning. It achieves state-of-the-art efficiency on each educational and inner benchmarks, impressed by real-world use circumstances from our trusted tester program.
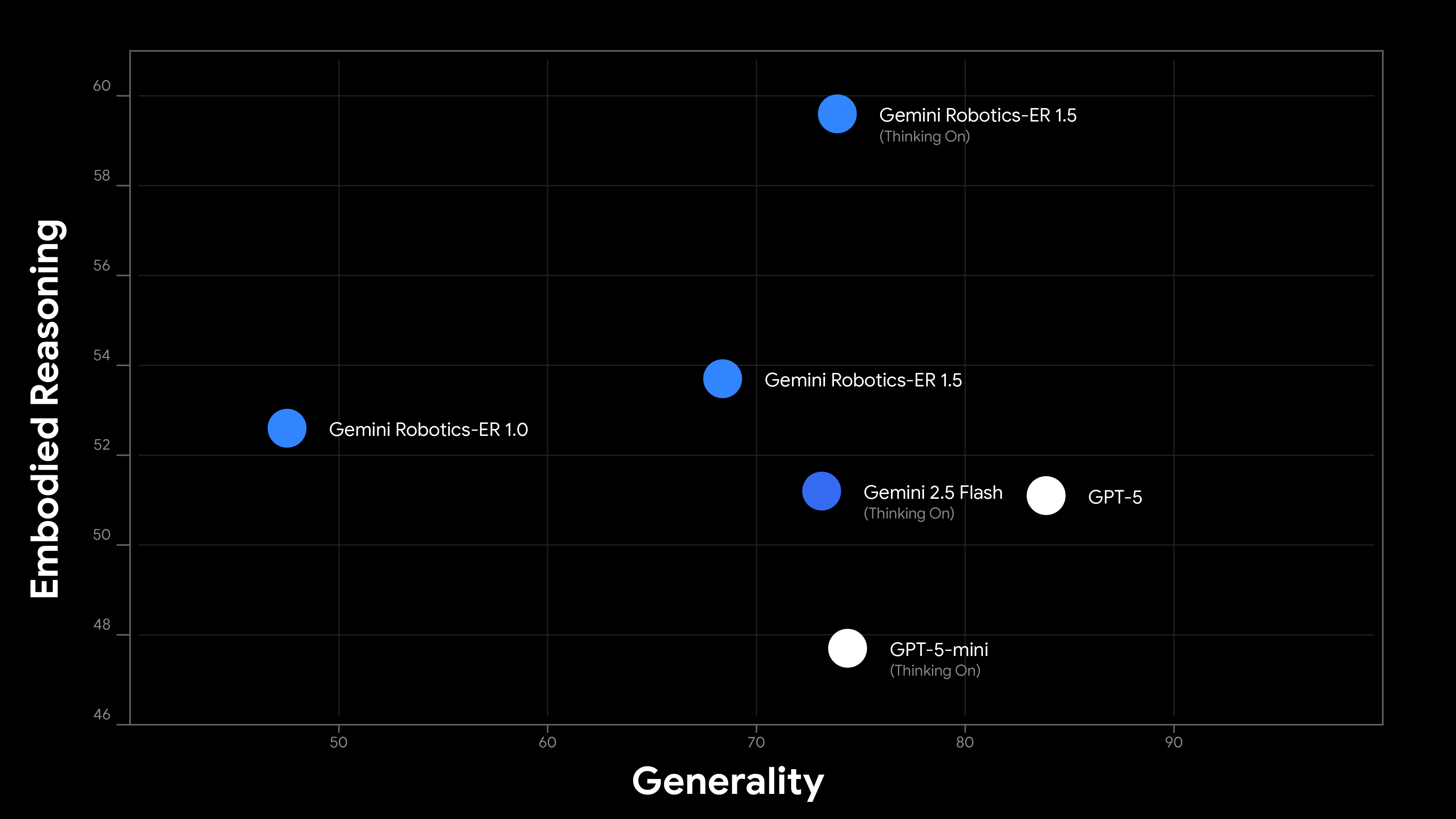
The Gemini Robotics-ER 1.5 mannequin is our most superior mannequin for embodied reasoning whereas retaining sturdy efficiency as a general-purpose multimodal basis mannequin. (Performance are measured as an aggregation on a set of embodied/common reasoning benchmarks, learn the tech report for extra particulars)
What’s New in Gemini Robotics-ER 1.5
Gemini Robotics-ER 1.5 is purpose-tuned for robotics purposes and introduces a number of new capabilities:
- Fast and highly effective spatial reasoning: Get state-of-the artwork spatial understanding on the low latency of a Gemini Flash mannequin. The mannequin excels at producing semantically-precise 2D factors, grounded in reasoning about merchandise sizes, weights, and affordances, enabling instructions like ‘level at something you may choose up’ for correct, responsive interplay.
- Orchestrate superior agentic behaviors: Leverage superior spatial and temporal reasoning, planning, and success detection for dependable long-horizon activity execution loops (e.g., “re-organize my desk according to this picture”). It may also natively name instruments just like the Google Search tool and any third-party user-defined features (e.g. “separate the trash into the correct bins according to local rules”).
- Flexible considering funds: You now have direct management over the latency vs. accuracy trade-off. This means you may let the mannequin ‘assume longer’ for a fancy activity like planning a multi-step meeting, or demand fast responses for a reactive activity like detect or level an object.
- Improved security filters: Build with better confidence. The mannequin has improved semantic security and is now higher at recognizing and refusing to generate plans that violate bodily constraints (e.g., exceeding a robotic’s payload capability).
An Agentic Brain for Your Robot
You can consider Gemini Robotics-ER 1.5 because the excessive stage mind in your robotic. It can perceive complicated pure language instructions, purpose via long-horizon duties, and orchestrate subtle behaviors. This means it excels not simply at notion, understanding what is in a scene and what to do about it.
Gemini Robotics-ER 1.5 can break down a fancy request like “clean up the table” right into a plan and name the precise instruments for the job, whether or not that is a robotic’s {hardware} API, a specialised greedy mannequin, or a vision-language-action mannequin (VLA) for motor management.
Advanced Spatial Understanding
In order for robots to have the ability to work together with the bodily world round them, they want to have the ability to understand and perceive the atmosphere the place they exist. Gemini Robotics-ER 1.5 is fine-tuned for producing prime quality spatial outcomes, permitting the mannequin to generate exact 2D factors for objects. Let’s check out a number of examples utilizing the Gemini GenAI SDK for Python that can assist you get began utilizing this mannequin in your individual purposes.
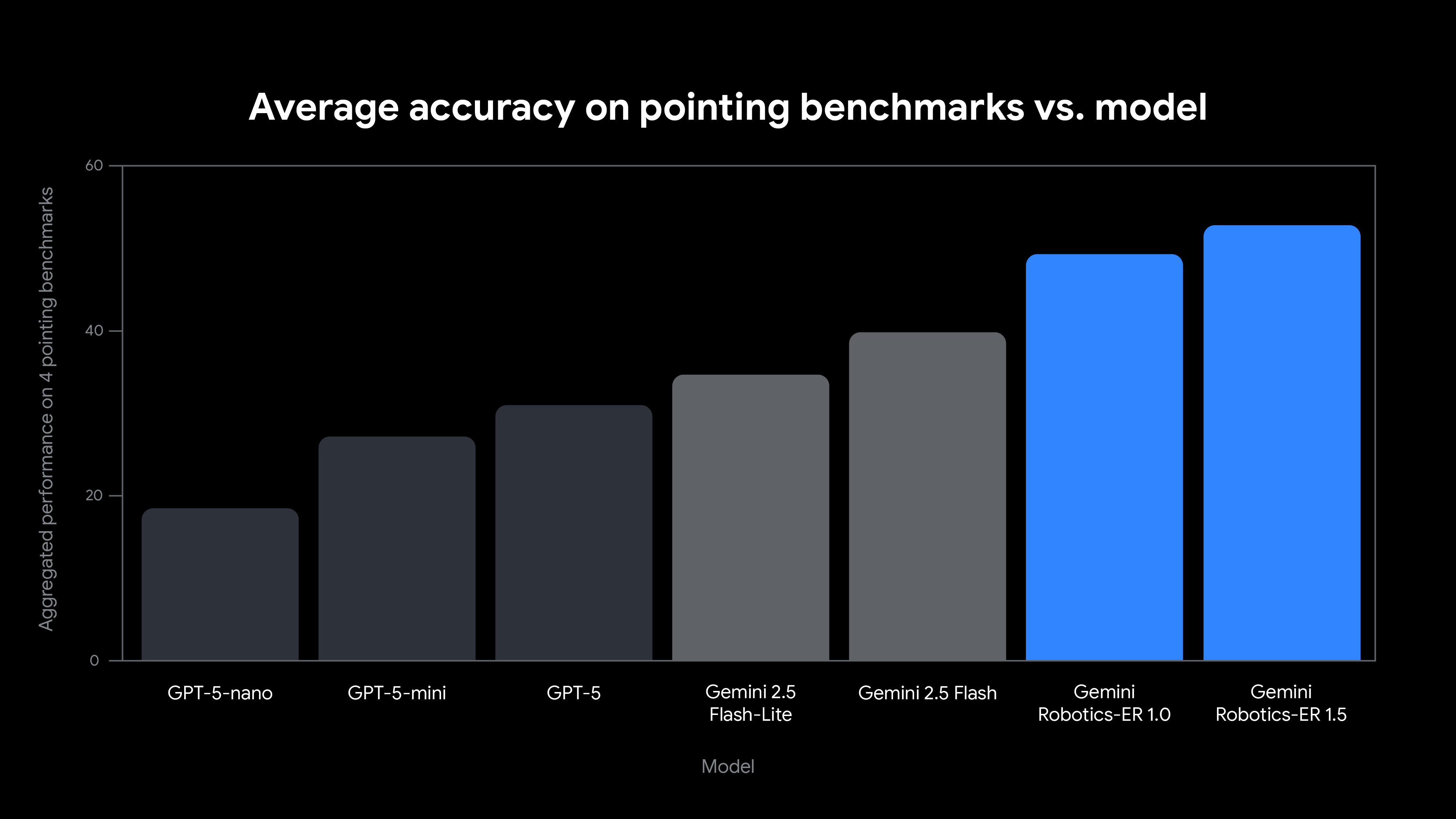
Gemini Robotics-ER 1.5 is probably the most exact vision-language mannequin for pointing accuracy.
2D Point Generation
Given a picture of a kitchen scene, Gemini Robotics-ER 1.5 can present the placement of each object (or a part of an object). This info can then be mixed with the robotic’s 3D sensors to find out the item’s exact location in area, enabling your planning library to generate an correct movement plan.

Point to the next objects within the picture: dish soup, dish rack, faucet, rice cooker, unicorn. The factors are in [y, x] format normalized to 0-1000. Only embrace objects which can be really current within the picture."Plain textual content
Note how we’ve requested the mannequin to solely embrace requested objects that seem throughout the picture – this prevents hallucinations, akin to together with some extent for the requested non-existent unicorn, and retains the mannequin grounded within the actuality of what it will possibly view. We can lengthen this method to outputting states of objects in a video stream, solely highlighting objects of a selected state, akin to a container being opened or closed, when it’s seen throughout the body. Below is a video of selling the mannequin to level to “green marker, brown tray, green notebook, laptop (open), laptop (closed), glasses case (open), glasses case (closed)”, which is a question that mixes spatial understanding and state estimation.
Temporal Reasoning
While finding objects is important, true spatial-temporal reasoning entails understanding the connection between objects and actions as they unfold over time. Gemini Robotics-ER 1.5 excels at this by processing video to grasp trigger and impact within the bodily world. For instance, within the following video, a pair of robotic arms strikes a inexperienced marker right into a picket tray, then strikes the blue and crimson pens into the cylindrical container. When we ask the mannequin to overview the sequence and inform us which duties had been finished in what order, in addition to what duties occurred between two timestamps, we obtain the proper reply. This demonstrates a capability to purpose about what occurred in a scene, not simply what’s in it.
Describe intimately every step of ending the duty. Breaking it down by timestamp, output in json format with keys "start_timestamp", "end_timestamp" and "description".Plain textual content
[
{
"start_timestamp": "00:02",
"end_timestamp": "00:13",
"description": "The left robotic arm picks up the green marker from the table and places it into the wooden tray."
},
{
"start_timestamp": "00:15",
"end_timestamp": "00:22",
"description": "The left robotic arm picks up the blue pen from the table and places it into the black mesh pen cup."
},
{
"start_timestamp": "00:23",
"end_timestamp": "00:28",
"description": "The right robotic arm picks up the red pen from the table and places it into the black mesh pen cup, completing the task of organizing the writing utensils."
}
]Plain textual content
>zoom into second 15 to 22 and supply a per-second breakdown of what’s taking place in the identical format
[
{
"start_timestamp": "00:15",
"end_timestamp": "00:16",
"description": "The left robotic arm begins moving towards the blue pen located on the table to the left of the pen cup."
},
... (removed for brevity, please take a look at the video below)
{
"start_timestamp": "00:21",
"end_timestamp": "00:22",
"description": "The arm lowers the pen into the cup and releases it, placing it upright inside the container."
}
]Plain textual content
The output is temporally correct, and overlaying it on the unique video reveals the mannequin has a exact understanding of the robotic’s movement.
Reasoning about affordances to orchestrate long-horizon duties
When considering is enabled, the mannequin can purpose about complicated pointing and bounding field queries. Here is a step-by-step demonstration of utilizing it in a espresso making instance. It demonstrates understanding of the “how” and “where” wanted for a human or robotic to complete a activity.

Identify the place I ought to put my mug to make a cup of espresso. Return a listing of JSON objects within the format: `[{"box_2d": [y_min, x_min, y_max, x_min], "label": Plain textual content

Where ought to I put the espresso pod?Plain textual content

Now, I want to shut the espresso maker. Plot a trajectory of 8 factors that signifies how the deal with of the lid ought to transfer to shut it. Start from the deal with. Points are [Y,X] in normalized coordinates [0 - 1000]. Please output all factors, together with the trajectory factors within the format. [{"point": [Y, X], "label": }, {"point": [Y, X], "label": }, ...].Plain textual content

I completed my espresso. Where ought to I put my mug now to wash up? Return a listing of JSON objects within the format: [{"point": [y, x], "label": Plain textual content

Here is one other instance of mixing planning and spatial grounding to generate a “spatially grounded” plan. It could be elicited with a easy immediate “Explain how to sort the trash into the bins. Point to each object that you refer to. Each point should be in the format: [{“point”: [y, x], “label”: }], where the coordinates are normalized between 0-1000.” The response comprises interleaved textual content and factors and it may be rendered out to create this animation.
Flexible considering funds
This chart reveals a sequence of examples of fixing the considering funds when utilizing the Gemini Robotics-ER 1.5 mannequin and the way that impacts latency and efficiency. Model efficiency will increase with an rising considering token funds. For easy spatial understanding duties like object detection, efficiency is excessive with a really quick considering funds, whereas extra complicated reasoning advantages from a bigger funds. This permits builders to steadiness the necessity for low-latency responses with high-accuracy outcomes for more difficult duties.
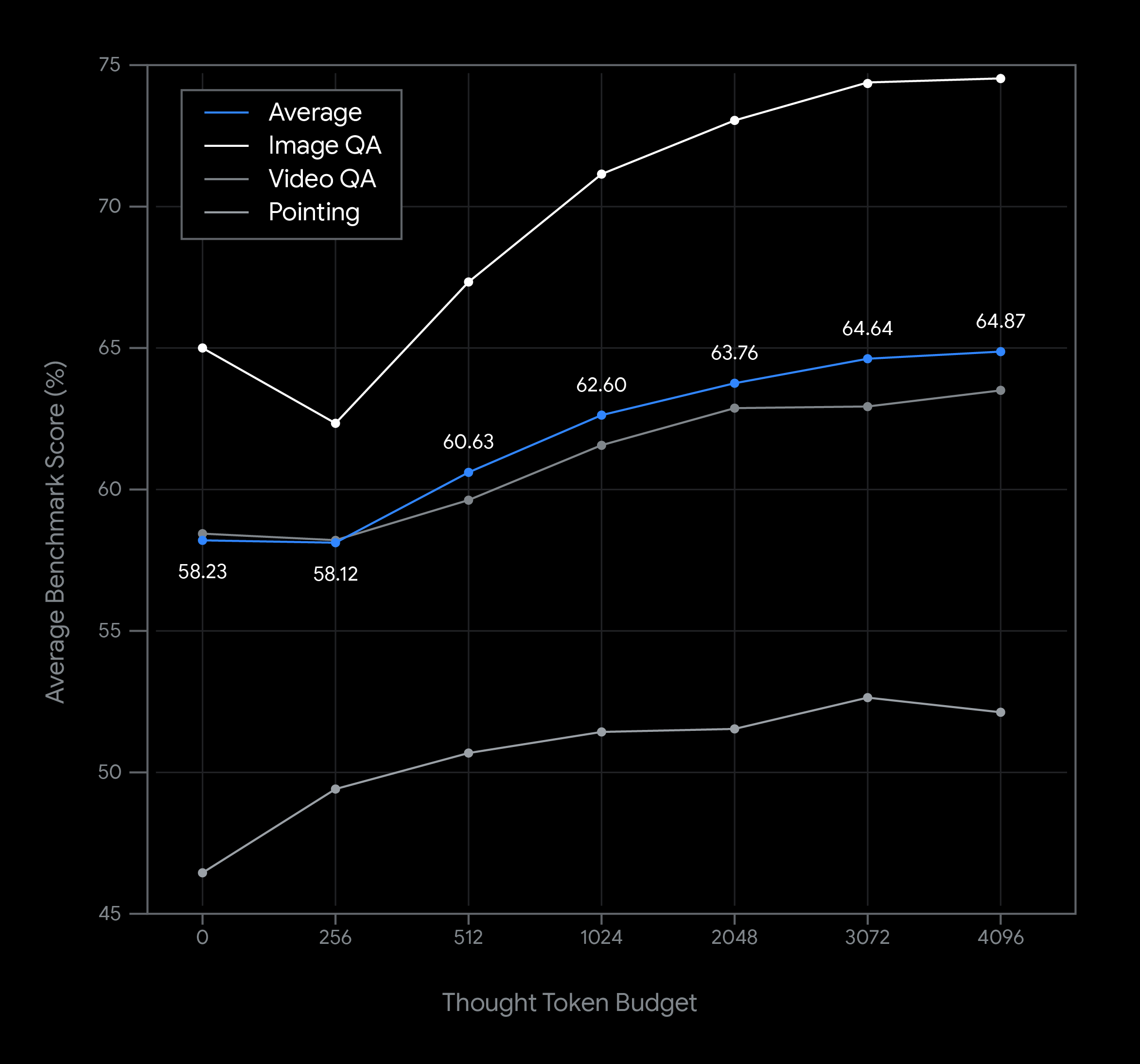
Gemini Robotics-ER 1.5 makes use of inference-time compute scaling to enhance efficiency. The considering token funds is tunable. This permits builders to steadiness the necessity between latency-sensitive duties with high-accuracy outcomes for more difficult reasoning duties.
While considering is enabled by default with the Gemini Robotics-ER 1.5 mannequin, you may set a considering funds, and even disable considering, by together with the thinking_config possibility together with your request. You can discover extra details about Gemini considering budgets here.
A Note on Safety
We are dedicated to constructing a accountable basis in your robotics purposes. Gemini Robotics-ER 1.5 has made vital enhancements in security, with enhanced filters for each:
- Semantic Safety: The mannequin is designed to grasp and refuse to generate plans for harmful or dangerous duties, with its capabilities rigorously evaluated in opposition to benchmarks just like the ASIMOV Benchmark.
- Physical Constraint Awareness: It is now considerably higher at recognizing when a request would violate a bodily constraint you outline, akin to a robotic’s payload capability or workspace limits.
However, these model-level safeguards usually are not an alternative choice to the rigorous security engineering required for bodily programs. We advocate for a “Swiss cheese approach” to safety, the place a number of layers of safety work collectively. Developers are accountable for implementing customary robotics security finest practices, together with emergency stops, collision avoidance, and thorough danger assessments.
Get Started Building Today
Gemini Robotics-ER 1.5 is on the market in preview right this moment. It gives the notion and planning capabilities it’s good to construct a reasoning engine in your robotic.
Dive Deeper into the Research
This mannequin is the foundational reasoning part of our broader Gemini Robotics system. To perceive the science behind our imaginative and prescient for the way forward for robotics, together with end-to-end motion fashions (VLA) and cross-embodiment studying, learn the research blog and full technical report.
This web page was created programmatically, to learn the article in its authentic location you may go to the hyperlink bellow:
https://developers.googleblog.com/en/building-the-next-generation-of-physical-agents-with-gemini-robotics-er-15/
and if you wish to take away this text from our website please contact us


